冒泡排序算法相对简单,容易上手,稳定性也比较高, 算是一种较好理解的算法,也是面试官高频提问的算法之一。
冒泡排序法的原理
基本原理
从序列头部开始遍历,两两比较,如果前者比后者大,则交换位置,直到最后将最大的数(本次排序最大的数)交换到无序序列的尾部,从而成为有序序列的一部分;
下次遍历时,此前每次遍历后的最大数不再参与排序;
多次重复此操作,直到序列排序完成。
由于在排序的过程中总是小数往前放,大数往后放,类似于气泡逐渐向上漂浮,所以称作冒泡排序。
原理图解
Tips:蓝色代表在一轮排序中等待交换,黑色代表在该轮排序中已交换完成,红色代表已排序完成
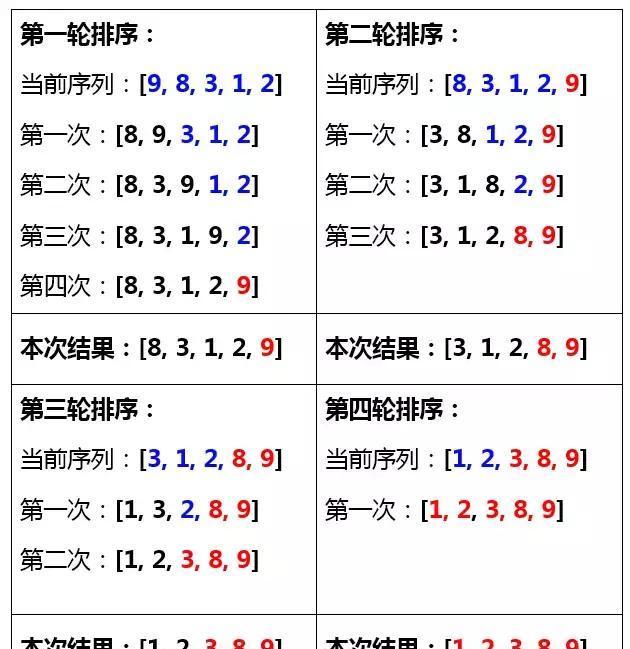
冒泡排序法的原理
实现冒泡的步骤分解
使用for循环确定排序次数
由于待排序的序列只剩下一个数时已经能够确定顺序,则无需进行排序,因此,排序次数为序列长度 – 1。

使用for循环确定排序次数
每次排序的比较次数控制
每次排序,序列中的多个数字要分别进行两两比较,多次的比较需要利用for语句来进行实现。该for循环嵌套于排序次数的for循环当中(形成双for的嵌套)。

每次排序的比较次数控制
Tips:j 需要设置为小于 len - i - 1,减i的原因是已经排序完成的数不再参与比较,减1的原因是数组下标索引值从0开始。
核心功能 — 两两比较并根据情况交换位置
比较两数大小,如果前者比后者大,则进行数值的交换,也就是交换位置。

两两比较并根据情况交换位置
冒泡排序法完整代码

冒泡排序法完整代码
冒泡排序法的优化
假如序列的数据为:[0, 1, 2, 3, 4, 5];
使用上面的冒泡排序法进行排序,得到的结果肯定没有问题,但是,待排序的序列是有序的,理论上是无需遍历排序。
当前的算法不管初始的序列是否有序,都会进行遍历排序,效率会比较低,因此需要优化当前的排序算法。
在如下的算法中,引入一个swap变量,每一次排序之前初始化为false;若发生两数交换位置,则将其设置为true。
在每次排序结束时候判断swap是否为false,如果是,则说明序列已排序完成或者序列本身是有序序列,就不再进行下一次排序。
通过此方法,减少不必要的比较和位置交换,进一步提高算法的性能。
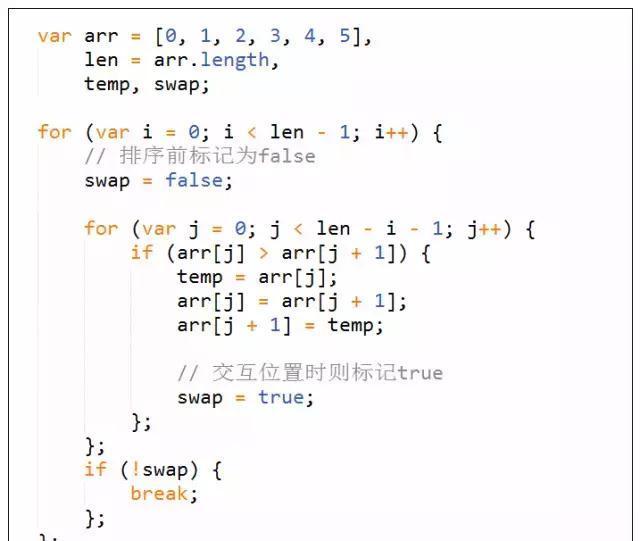
冒泡排序法的优化
冒泡排序法的效率
时间复杂度
最佳状态:待排序的序列本身是有序序列,排序次数根据优化后的代码,可以得出是n-1次,时间复杂度为O(n);
最坏的情况:待排序的序列是逆序的,此时需要排序1 + 2 +3 ……(n - 1) = n(n – 1 )/2次,
时间复杂度为O(n^2)。
空间复杂度
冒泡排序法需要一个额外空间(temp变量)来交换元素的位置,所以空间复杂度为O(1)。
算法的稳定性
当相邻元素相等时,并不需要交换位置,也就不会出现相同元素的前后顺序发生改变,所以,是稳定性排序。
O是个啥?!
时间复杂度,更准确的说该是描述一个算法在问题规模不断增大时对应的时间增长曲线。所以,这些增长数量级并不是一个准确的性能评价,可以理解为一个近似值。(空间复杂度同理)
O(n)表示当n很大的时候,复杂度约等于Cn,C是某个常数,简单说就是当n足够大的时候,随着n的线性增长复杂度将沿平方增长。
O(n)表示,n很大的时候复杂度约等于Cn,C是某个常数。简言之:随着n的线性增长,复杂度沿线性级别增长。
O(1)表示,n很大的时候,复杂度基本就不增长了。简言之:随着n的线性增长,复杂度不受n的影响,沿常数级别增长(此处的常数是1)。
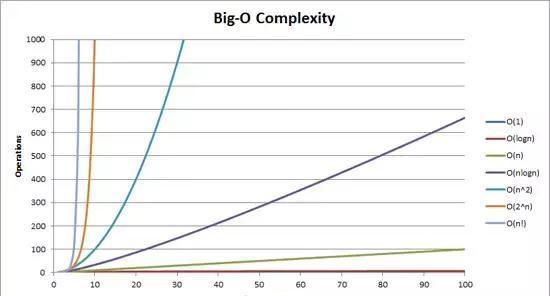
O是什么?
Tips:图中O(1)紧贴着X轴,并看不太清楚。
Tips:该图来源于“Stack Overflow”网站。